
**Guest post by Tim Shipp ** First and most importantly, huge thank you to Tim for allowing me to do this. You’re the best!Quick background on myself and the environment. I am a Systems Engineer for a company in seacoast New Hampshire. I have been working in IT for a while, and in the VMware ecosphere since 2006. I have worked in the insurance realm, global enterprise, airline, and managed services. The environment this issue was seen on is newly built. My colleague and I built the infrastructure and deployed View 7.4 onto vSphere 6.5 over the last month. There are approximately 15 desktop pools. Most are Linked Clone persistent desktops running Windows 7.
Now the story……
On 10/1, I was kicking the tires with Vester
. I noticed that HA had not been enabled on the desktop cluster. I let the other SE know what I saw and that I was enabling it. So I ticked the box and went on my merry way. (Don’t yell at me about change control!)On 10/2 at 11:38 AM, we received a page that one of the new desktop hosts had lost connectivity with vCenter. I logged in, and yes, it was disconnected, but it responded to pings. About 2 or 3 seconds later, it showed connected again, no harm no foul. So I looked at the uptime, it said 16 days. That said to me, there was an agent restart. However, two VMs did HA hot-migrate off. We figured it was an agent issue though. We saw the only task that had run was a VM disk reclamation that had failed.At 12:37, we received a page that a different host had lost connectivity with vCenter. Again, this one responded to ping, yet was offline in vCenter. Again, 3 or 4 seconds later, it came back in, and the uptime was 16 days. Also, the same disk reclamation task failed; 7 or 8 VMs again migrated out of 60 on the host.So at this point I figured something was “wrong”. So like any good SE I start looking at logs. Thank goodness I had set up vRealize Log Insight
a week before. ASIDE: If you’re not using vRLI, you should be. It’s made log review less painful for me and actually allowed me to find root cause quickly.Anyway, I knew the time, so it was easy. I saw this in the logs: 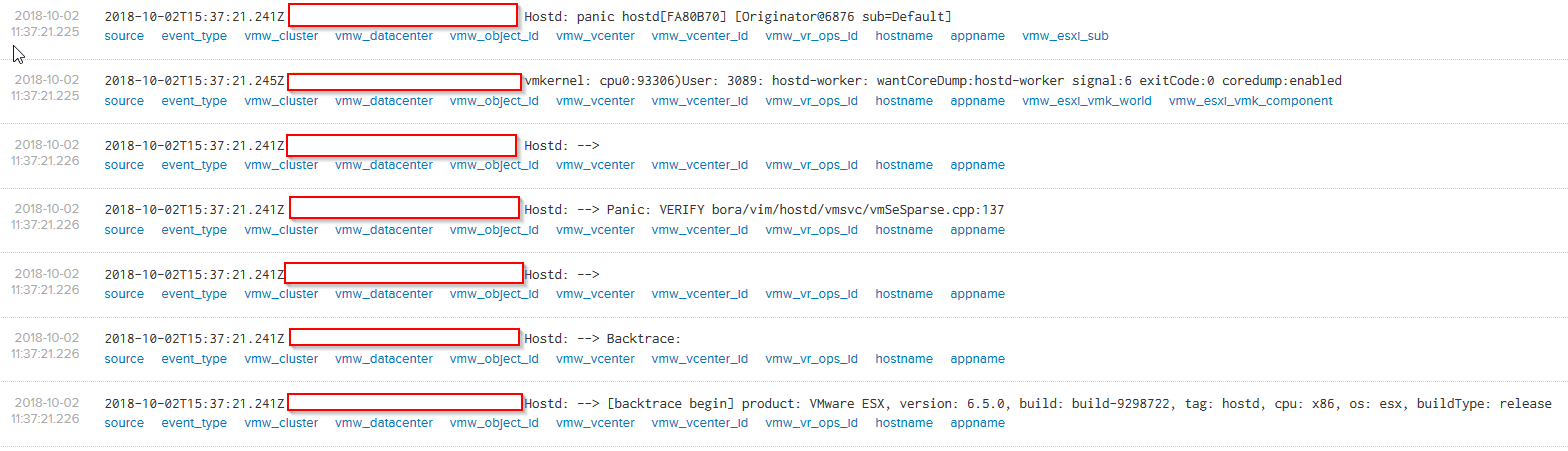 Hmmm, hostd crash and coredump, that’s not good. A little further down…..
Hmmm, hostd crash and coredump, that’s not good. A little further down…..  And there are some fdm events in there as well, the VMotions I saw. So while I was looking at these, at 13:38, exactly an hour later, it happened again. Same symptoms and same disk reclamation task failure, and VMotions.So what do I do? Well ask the Google of course. Unfortunately there is nothing. Zero, zilch. No KB’s, nothing. So I went into the pool, disabled space reclamation, which it is disabled on all of the other pools anyway per Pure Storages VDI best practices.Next up, open an SR with VMware. So I run off, collect logs from both hosts, and open a ticket. After one day, and one escalation later VMware support returns with this:
And there are some fdm events in there as well, the VMotions I saw. So while I was looking at these, at 13:38, exactly an hour later, it happened again. Same symptoms and same disk reclamation task failure, and VMotions.So what do I do? Well ask the Google of course. Unfortunately there is nothing. Zero, zilch. No KB’s, nothing. So I went into the pool, disabled space reclamation, which it is disabled on all of the other pools anyway per Pure Storages VDI best practices.Next up, open an SR with VMware. So I run off, collect logs from both hosts, and open a ticket. After one day, and one escalation later VMware support returns with this:
I analyzed the logs and found a crash dump file for the hostd. Analyzed the crash dump and found the below entries - Starting debug session using /build/apps/bin/debugzilla.py with hostd-worker-zdump.000. Timeout: 240 seconds Debug session is Ready.. Dump is from: hostd Build Number: 9298722 (6.5.0 - vsphere65ep8) Results from the debug routines - Total Modules Run: 56. Matched Modules: 1 Matched Module: PR_2095915_Checker Result: Host crash while running wipedisk routines on non-persistent disks. Read PR 2095915 for investigation details Resolution: Investigation in progress. Please watch the progress of PR: 2095915). Disabling “Space Reclamation” on Horizon View can be a temporary workaround T his is a known BUG with horizon view which causes host to get disconnected during a space reclamation process. The engineering team is still working on it and unfortunately there is no fix defined for this issue yet. The work around available is to disable space reclamation. Screenshot of the above debug result is attached to this email. Please reply to this email in case of any further questions or advise if we can temporarily archive this ticket.
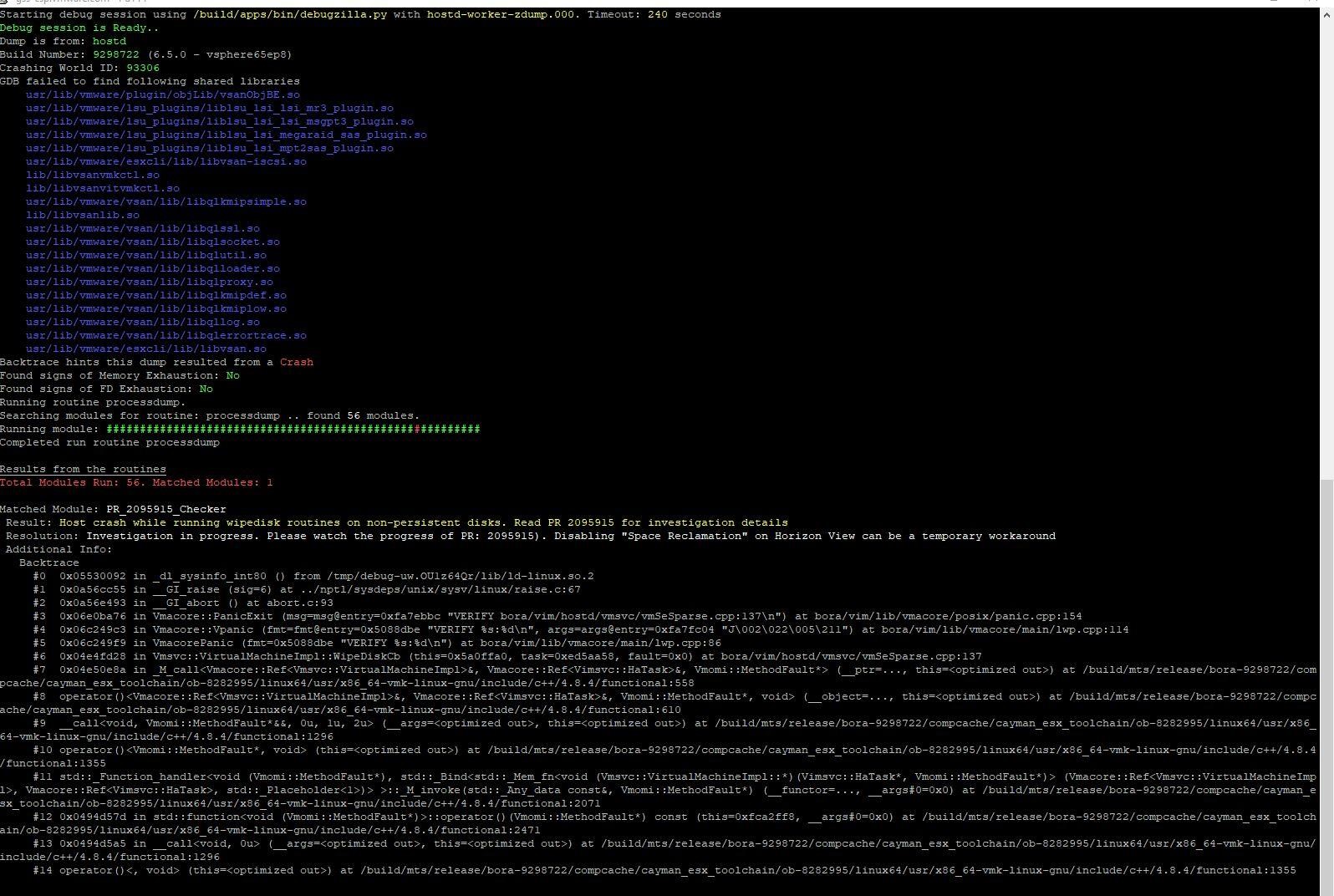
Conclusion:
So, it’s a known BUG, but not listed anyplace, that I have been able to find. Internal KB maybe? But this seems like not small, so I figured others might find it useful.We had not experienced the bug until we enabled HA. I believe it crashes the fdm service first, then hostd and vpxa are taken down. So if you have space reclamation ON, and running Horizon 7.x on vSphere 6.5, I’d turn it off if I was you.