
Who is the middle man? In a lot of circles, the middle man is someone that is a threat. The man in the middle attacker, the one who takes your data in transit and uses it for nefarious purposes. In other circles, he’s seen as the useless figure in a transaction. Someone who is preventing you from getting what you want directly from the source, instead forcing you to deal with the terms and conditions they set. Sometimes the middle man is no person, but is software - like middleware. Software that allows one platform to communicate with another by translating the data between the two systems. But recently, I’ve been introduced to a new middle man. One who deals in an area I didn’t think middle man should be, and you know what? I like him!
The Middleman:
DriveScale is that middleman, but without any of the negative connotation that may exist with that title. Their purpose is to change the way that hadoop clusters are scaled and upgraded. By scaling disk and compute separately, DriveScale enables customers to upgrade to faster compute nodes, without the need to rip and replace the storage as well. While I’m not familiar with hadoop clusters enough to talk about preferred architecture, performance points, or things of that nature; I was impressed at how DriveScale can make a hadoop cluster very agile. By working as the middleman between storage and compute, they allow the hadoop to be consumed in a cloud like fashion. Selecting compute nodes based on policies to ensure they meet your requirements, and then selecting disks that meet policy requirements; Drivescale handles all the work of attaching those disks to those nodes, and after a few clicks, those nodes are ready to go.

The Design:
Unlike normal VM HCI deployments, hadoop clusters require storage to be able to scale independent of compute. Compute nodes are now only purchased with disks for OS, and not for data. Disks, in turn, are purchased in JBOD devices. Those JBOD arrays are then connected to the DriveScale appliances via multiple 12gb/s SAS connections. The DriveScale appliances use a modern UI and a policy-driven architecture to allow storage to be provisioned as needed to the system. DriveScale will go out and automatically connect the compute to the storage via iSCSI, all without any additional user intervention. This allows the administrator to spend less time doing busy work connecting and disconnecting storage as needed.
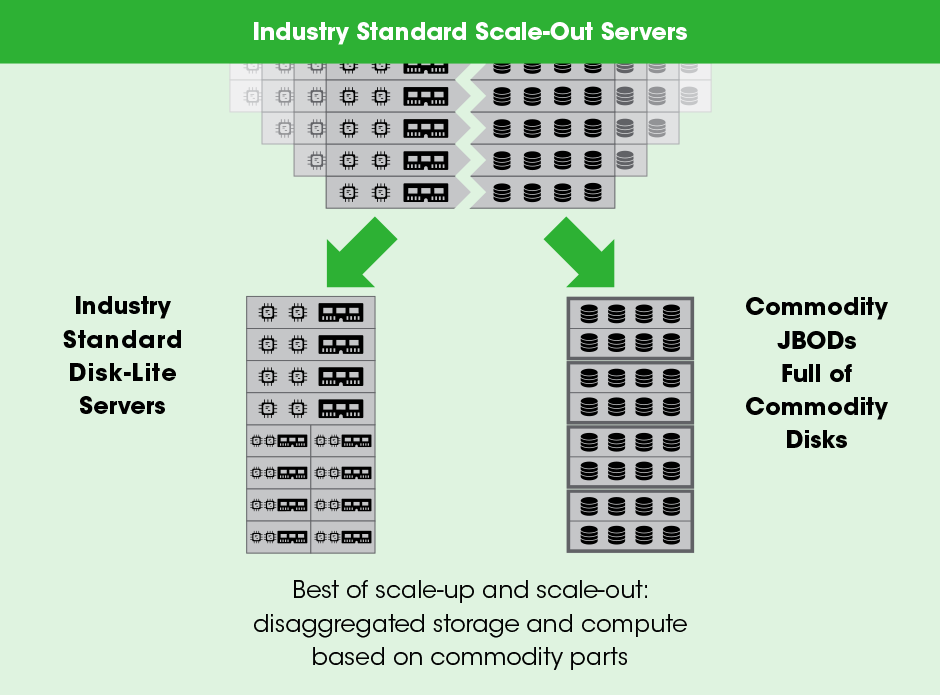
The Hardware:
Each Appliance is a 1U device, with 4 connectivity planes on the back, each with 2 x 12gb/s SAS connections, and 2 x 10gb/s network connections. The SAS connections allow for multiple JBOD enclosures to be connected. The 10gb/s NICs will be connected to the ToR (Top of Rack) switches. On the front is the compute portion, as well as some flash storage for acceleration. The systems is designed to drive scale (hence the name) so multiple appliances and racks are managed as a single entity.



The verdict:
Hadoop is certainly not my area of expertise, but the design makes sense. By using commodity hardware and drives, and using DriveScale to leverage that storage in a way not previously possible, it’s a sound investment for big data. With additional technologies, like a SAS-Ethernet bridge, which allows each disk to act as an independent iSCSI server, the company is certainly making an investment in thinking outside the box.
All travel expenses and incidentals were paid for by Gestalt IT to attend Tech Field Day 12. Additionaly, DriveScale provided a gift to all delegates but with no expectations about the coverage through this blog or social media.