
With a wide range of deduplication appliances out there for a backup target, one option is simply server 2012. Server 2012 has a deduplication feature now, that is set per volume, and can offer great results when used as a backup repository for Veeam.
See Justin’s Post for setting up dedupe on Server 2012.
Veeam has excellent per job inline deduplication, which ensures that each backup file is not storing redundant data. By using that in conjunction with Server 2012 per volume deduplication, we can achieve up around 70% and more deduplication. That’s some big savings!
Server 2012 dedupe algorithm is quite interesting. It takes files and breaks them into variable chunks, ranging from 32kb - 128kb. Using this algorithm, we can break up files into common chunks and store them once.
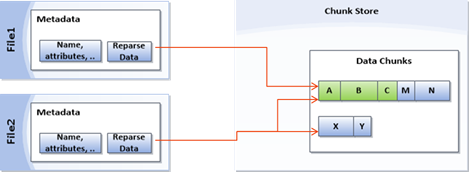
Veeam Options for Dedupe Storage
Veeam has 2 options for dedupe storage repositories.
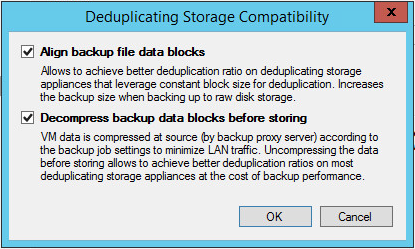 Align backup file data blocks - The explanation above sums it up. By aligning the blocks, we can ensure that our chunks are consistent, making it easier for Server 2012’s algorithm to get its variable chunks out of the backup file.
Align backup file data blocks - The explanation above sums it up. By aligning the blocks, we can ensure that our chunks are consistent, making it easier for Server 2012’s algorithm to get its variable chunks out of the backup file.
update: Veeam recommends not using the Align backup file data blocks with Server 2012, as the variable length chunks don’t require alignment. It is possible that by aligning, you will decrease your deduplication rate slightly.
Decompress backup data blocks before storing - While this seems counter productive, it’s actually quite beneficial. When we have them compressed, it’s harder to find similar chunks to dedupe, but by allowing them to sit uncompressed, Server 2012 has a much better chance of getting similar chunks.
The results:
My lab is running slim right now, so I only tested with a handful of VMs, but you will notice a difference when using both options above.
No Options Selected:
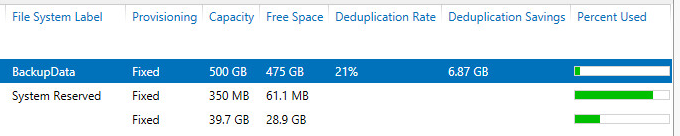
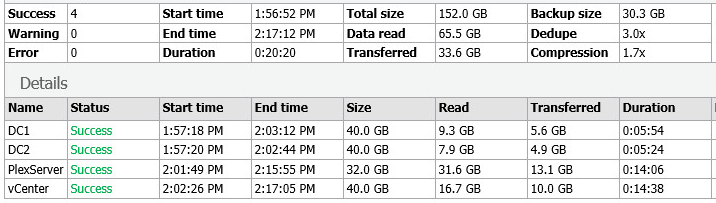
Align data blocks only:
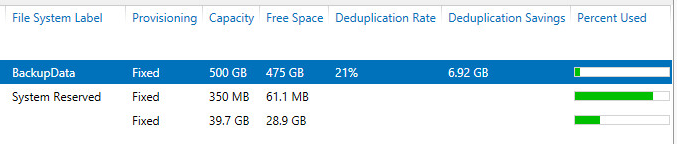
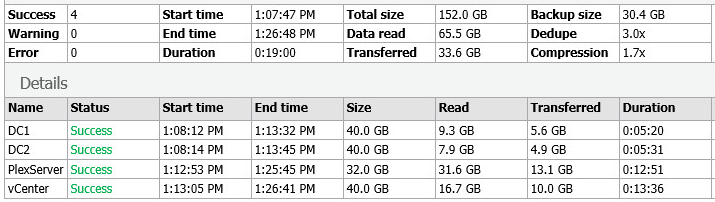
Both options selected:
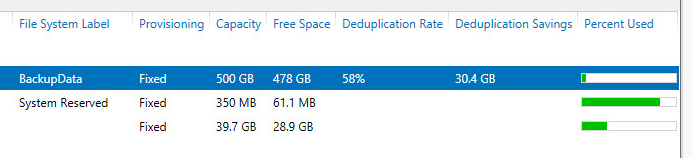
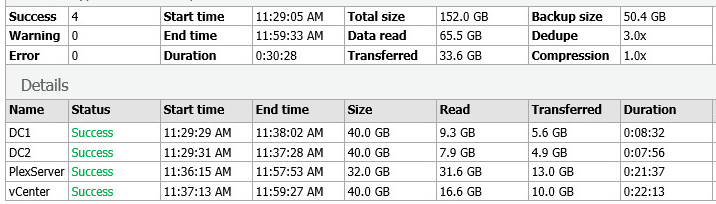
So what does it mean?
Looking at the Backup Size, and the deduplication savings and free space, we can see that by selecting both options, we have the following:
- Backup data transfered remains the same through all jobs
- Backup size is larger by 20 GB due to decompression
- However, I got much better dedupe rates even with writing more data to the repository, and am now storing less data.
These results are just for 1 full backup. Where this will really shine is over time, and especially if you have multiple Veeam backup jobs. Remember, Veeam dedupes per backup job, you don’t get deduplication of multiple jobs, and incremental jobs after the first - but by using Server 2012 dedupe, you will!