
.
Disaster Recovery. It’s a phrase that’s tossed around IT circles like candy at a parade. Everyone wants it, and lots of vendors offer it. What exactly is it? Seems simple enough to answer – Disaster Recovery is the ability to recovery from a disaster, and in our case, recover data and systems. But, what constitutes a disaster?
Tornado, flood, hurricane, fire – these are our typical “smoking hole” scenarios, and are usually what comes to mind when we think of the “disaster” in disaster recovery. But what about others? Are disasters limited to naturally occurring disruptions? Aren’t all disruptions to the business some form of disaster?
Most organizations seem to have some sort of DR implementation when it comes to these larger disasters. Sometimes it’s as simple as offsite backups on one side of the spectrum, and as complicated as hot sites and stretched clusters. Depending on business needs and costs, both could meet business requirements.
When it comes to disaster recovery, there is no “one size fits all” solution. Every organization has different requirements, budgets, business needs. These all dictate RPO (Recovery Point Objective) and RTO (Recovery Time Objective). RPO is the amount of data loss that is acceptable when recovering an application. Some enterprise applications have a RPO of zero (Especially when financial transactions are involved), while less important applications may have a RPO of days. RTO is the acceptable time that the application can be down during the recovery process, or “It shouldn’t take any longer than X to get the application back online.”
With all the different requirements, and all depending on each organization’s individual needs, there still exists one thing that they all need:
A Documented Disaster Plan.
I find that too often, some sort of solution is in place, but no documentation exists on what to do in the event of a DR scenario. That’s why if an organization has data they can’t be without – they need a documented DR Plan, or Playbook. This DR Plan is no small feat to create, and in fact can sometimes take more effort than implementing the replication methods used. At a minimum, every DR Plan should include the following information:
- Emergency contacts
- Emergency Services (Fire, etc)
- Building
- Electrician
- IT Team
- Application owners

- Vested business contacts (CIO, etc)
- Hardware / Software support information
- Network – Route / Switch
- Storage, SAN
- Compute
- Hypervisor
- OS
- Application
- WAN Circuit(s) support information
- Domain Registrar and external DNS
So, where to start when building the Plan? I find the best way to start is to outline a TOC (Table of Contents) and then fill in the dependencies from there. The first section should be Emergency contacts, and like the DR scenarios, these should be listed out in a hierarchy. Here’s a small sample of a TOC for a fictional company:
Acme Disaster Recovery Plan
Table of Contents:
Emergency Contacts
Support Information
………Hardware
………Software
………WAN / External Services
Disaster Scenarios
………Chain of command
………Full site failure
………Storage failure
………WAN failure
………Application failure
………………AD
………………Exchange
………………ERP Cluster
………………Accounting
………………Web portal
As you can see, just a small sample of possible scenarios are listed. Let’s dive a little deeper into those.
Chain of Command – while this isn’t a scenario, this section is needed to outline who calls the shots. In some scenarios, someone will need to determine when to failover, restore from backup, or accept data loss. The chain of command will outline the hierarchy of people who make those decisions. This information will be included for individual applications as well.
Full site failure – This section should include all the information to completely fail over the site. Contacts to be notified of the disaster, and affirmation of DR actions as well as verbose steps for using the failover solution to bring the full site online at the remote location, and to move all WAN services to that location.
Storage / WAN failure – Other possible scenarios where a full site failover may not be needed. While not limited to just storage and WAN services, these scenarios are major events, but may not require a full site failover. Contacts, Chain of Command, and possible steps taken will be listed in this section, as well as downstream dependencies, such as applications that rely on WAN services.
Application Failures – This list should include every application that the business relies upon. Not all application downtime will cost the company money, so some application may be excluded here. Each application should have the Application owner contact information, Chain of Command, and various actions to restore the application services. Remember, you may outline multiple action steps for an individual application, such as remote failover, local failover from a previous point in time, or restoration from backup. This is also a great section to include application dependencies, to ensure that the application will be fully available when failed over.
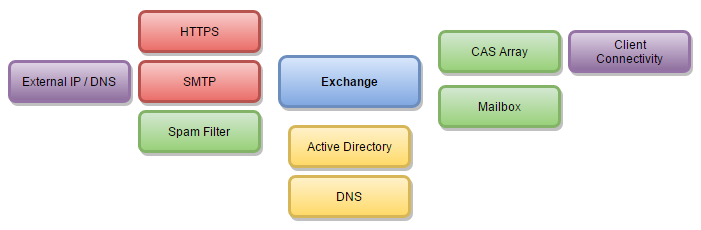
A failback section will be needed for each to insure that services can be moved back once the site or supporting hardware is restored.
The plan is now in place, and it is important to now start testing. While replication solutions have online testing by bringing the environment up in a sandbox, nothing can compare to the value of a live failover test. With a live test, the plan can be put into action, and missed areas can be addressed, corrected, and then documented into a revised DR plan. Some commonly missed areas are around the services that support applications, such as: Active Directory, DNS, NTP Servers, and others.
With all the money invested in DR hardware, remote sites, replication solutions, time also needs to be a sound investment in a successful disaster recovery plan. With a well prepared DR Plan in place, the guesswork gets removed during the critical moments of failover and recovery.
{kind=link}